DeepSeek引爆AI价格战:V4系列输入成本暴跌90% 开启国产化新纪元
2026-04-27 10:11:57未知 作者:徽声在线
徽声在线记者 | 宋佳楠
DeepSeek正以突破性举措重塑大模型市场的价格基准,为AI普惠化进程按下加速键。
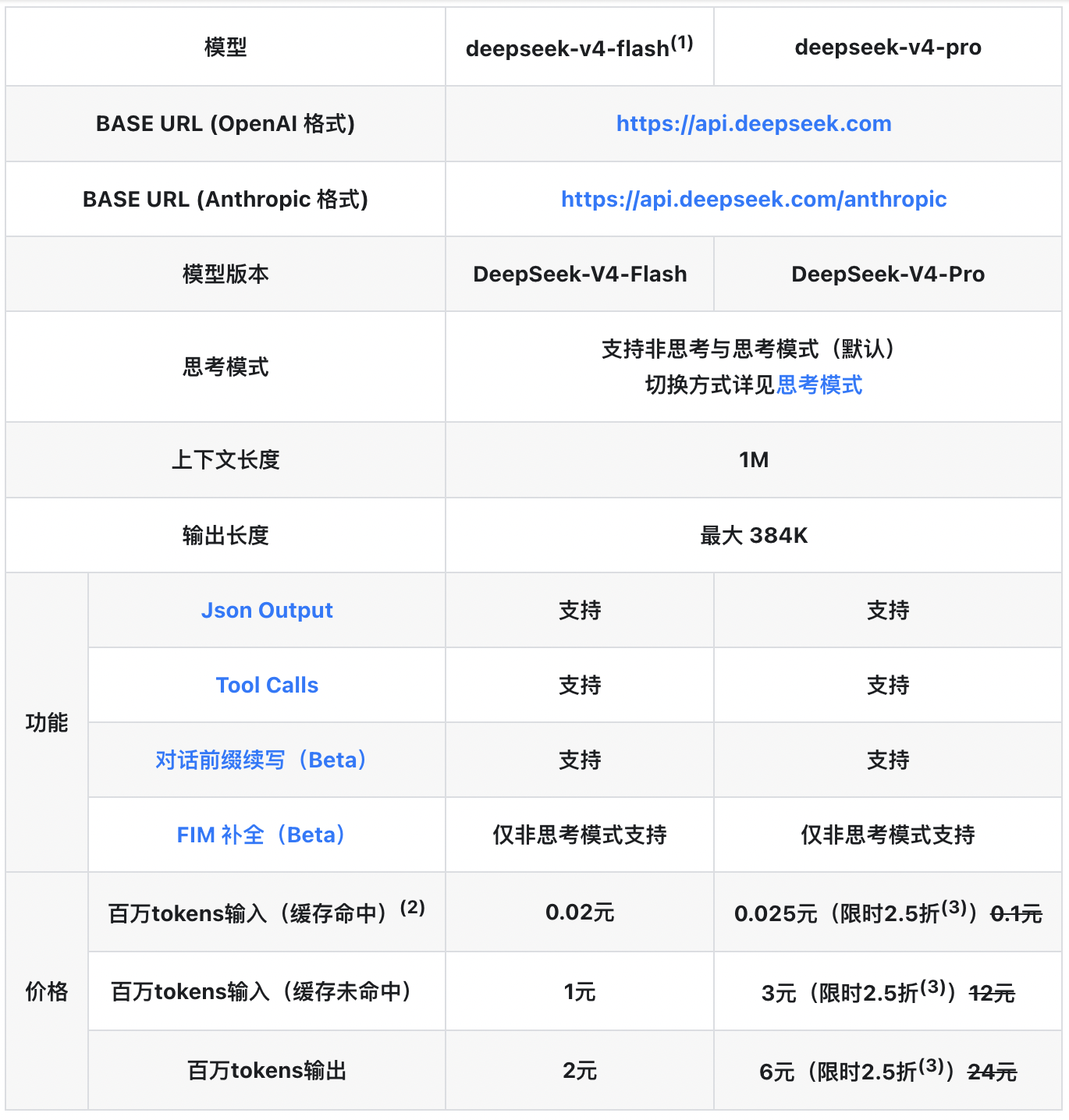
4月26日,DeepSeek官方发布重磅API调价公告,全系产品输入缓存命中价格实现指数级下降,其中V4-Pro版本叠加限时2.5折优惠后,百万Tokens输入成本低至0.025元,较首发价暴跌90%,这一价格不仅刷新全球大模型最低纪录,更标志着AI商业化进入「厘时代」。据行业分析,此次降价将直接推动智能客服、知识库构建等高频应用场景的运营成本下降超90%,为AI技术规模化落地扫清关键障碍。
根据最新定价体系,V4系列全模型均纳入降价范围:DeepSeek-V4-Flash输入缓存命中价从0.2元/百万Tokens降至0.02元,企业级旗舰模型DeepSeek-V4-Pro原价1元/百万Tokens的缓存输入降至0.1元,配合2026年5月5日前有效的2.5折限时优惠,实际成本仅0.025元/百万Tokens。更值得关注的是,缓存未命中场景的输入价格从12元降至3元,输出价格从24元降至6元,形成全链路成本优化矩阵。
<
图片来源:DeepSeek官网
在模型架构调整方面,DeepSeek宣布将逐步淘汰DeepSeek-Chat与DeepSeek-Reasoner两个旧模型名称,未来将统一采用V4-Flash的非思考模式与思考模式进行区分。这一变更既保持了技术兼容性,又为模型迭代预留了清晰的发展路径。
技术降本的底层逻辑在于DeepSeek-V4系列实现的三大突破:首先,自研稀疏注意力架构使推理算力消耗显著降低,Pro版单token算力需求仅为V3.2版本的27%,KV缓存占用空间压缩至10%;其次,100万token超长上下文支持能力通过创新的token维度压缩技术实现,结合DSA稀疏注意力机制,在保持全球领先长文本处理能力的同时,将计算资源需求降低40%;最后,与华为昇腾生态的深度协同开发,使模型在国产化硬件上的运行效率提升1.5-1.96倍,为后续成本持续下探奠定基础。
从模型参数配置看,V4-Pro与V4-Flash形成差异化布局:前者激活参数达490亿,预训练数据规模33TB,定位高性能旗舰;后者激活参数130亿,预训练数据32TB,主打高速响应场景。在Agentic Coding评测中,V4-Pro已达到开源模型最佳水平,内部使用反馈显示其交付质量接近Claude Opus 4.6非思考模式,但在复杂逻辑推理场景仍与思考模式存在差距。世界知识测评结果显示,V4-Pro领先其他开源模型,仅逊色于Gemini-Pro-3.1;在数学、STEM及竞赛代码领域,则与顶级闭源模型比肩而立。
值得关注的是,V4系列开创的混合注意力机制通过动态压缩token维度,结合稀疏注意力分配策略,在保持模型精度的同时,将显存占用降低60%。这种技术突破使得在消费级显卡上运行百亿参数模型成为可能,为边缘计算场景开辟新路径。昇腾超节点全系列产品的适配支持,更释放出明确的国产化信号——技术报告显示,在英伟达GPU与华为昇腾NPU双平台验证中,细粒度EP方案实现1.5-1.96倍加速,特别在强化学习等延迟敏感场景表现突出。
资本市场对此反应积极,高盛最新报告指出,DeepSeek V4通过成本重构打破了AI应用落地的「不可能三角」,使复杂智能体商业化成为现实。随着昇腾超节点下半年批量上市,Pro版价格有望进一步下探,形成「技术升级-成本下降-应用扩张」的正向循环。报告特别强调,在芯片出口管制背景下,中国头部AI企业向国产算力迁移的趋势获得产业验证,这或将重塑全球AI基础设施竞争格局。
投资领域动态同样引人注目,据知情人士透露,腾讯与阿里正就超过200亿美元估值投资DeepSeek展开谈判,这一数字虽低于智谱(530亿美元)和MiniMax(310亿美元)的当前市值,但反映出互联网巨头对顶层AI能力的战略布局。华泰证券分析认为,市场不应简单将V4理解为成本压缩,其真正价值在于长上下文成本下降后,复杂Agent、多文档分析等场景的可用性提升,预计将带动推理调用量增长3-5倍,存储访问频次增加2倍以上。








